Important community update: Klaw's latest actions to enhance transparency
We, as an integral part of the Klaw open-source project, are committed to upholding the true spirit of open-source values. To ensure transparency and foster trust within our community, we have an important update to share.
Discovery of legacy tracking code:
We recently identified a piece of legacy, non-functional tracking code within our codebase. This code, originating from a previous version of our project, used Google tag (gtag) for analytics purposes. It was designed to track various user interactions on our site, including page views, scrolls, outbound link clicks, file downloads, video plays, site searches, and form interactions.
Scope and deactivation of the tracker:
This tracking code was specifically configured to gather data from kafkawize.com. We want to reassure our community that this means that no data from any other host has been or is being collected, accepted or stored by this code. As of February 2022, this configuration has been completely removed.
Impact on users:
We are pleased to inform you that the legacy code has not affected our newer Coral React UI. This interface, representing the latest development of our platform, remains free from any impact of this outdated tracking code.
In commitment to our community's transparency, we are releasing software updates 2.5.2 and 2.6.1. These versions aim to completely remove this legacy code, allowing our users to transition to a version where their privacy and trust are further safeguarded.
Your feedback is important. Stay updated and reach out to us via GitHub for any queries or suggestions.
This article explores the significance, evolution, and management of schemas in Klaw. It also covers how Klaw safeguards
organizations against data loss by creating schema backups for disaster and failure recovery.
Data governance is becoming increasingly important for organizations that want to improve data quality, comply with
regulations, and strengthen security. One way to achieve this goal is by setting up internal benchmarks, regulations
for data, and schemas.
Schemas provide a clear understanding of what to expect from information, guiding their engagements and the
relationships among objects. This guidance enables streamlined access, modification, and querying of data.
Furthermore, a schema outlines both the visual representation and structural organization of the data.
Within the Apache Kafka ecosystem, schema registries such as Karapace and Confluent's Schema Registry play a key role in the
management and validation of schemas. Furthermore, they provide a RESTful interface to manage schema and their evolution
processes effectively.
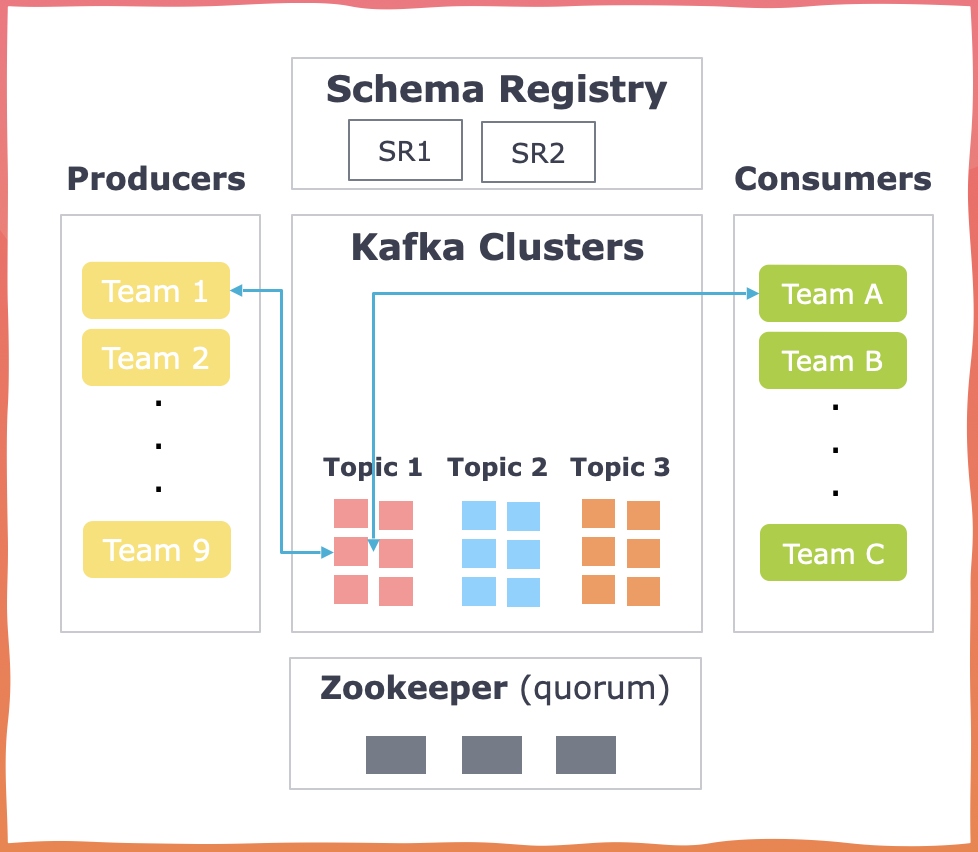
Apache Kafka is a distributed streaming platform that allows producers to write data to topics and consumers to read
from them. When there are structural changes to the data, it is important to establish an understanding between the
producers and consumers to ensure that events are processed successfully.
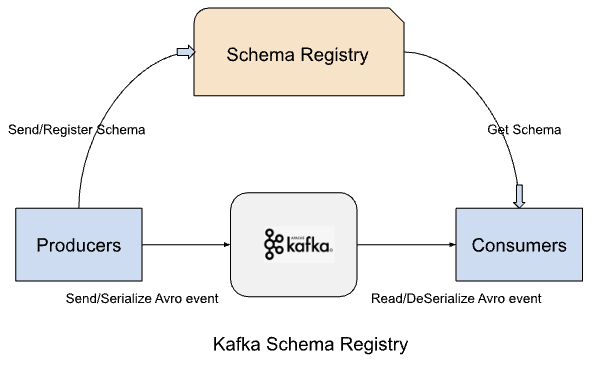
The below image depicts the communication between Schema Registry, Apache Kafka, producers, and consumers.
Producers can register a schema based on a specific configuration, or they can use the REST API provided by the Schema
Registry. During this process, events are serialized and validated against the currently registered schema.
Subsequently, consumers deserialize the event and transform it into a standardized record in line with one of the
registered schemas, as determined by the consumer's settings.
In Apache Kafka events, you can create schemas for both keys and values, allowing the generation of key schemas and value
schemas. When a schema is registered, it is automatically stored in the default _schemas Apache Kafka topic and is assigned
a unique identifier.
If the same schema is registered on another topic, it will link the previously registered schema using the same
identifier. This identifier becomes an integer value generated upon successfully registering the schema.
To retrieve a schema based on an id: GET /schemas/ids/{int: id}/schema
Apache Kafka offers various strategies for schema registration, with the default being the TopicNameStrategy. In this
approach, the subject name corresponds to the Apache Kafka topic name. In this strategy, typical subject names include
"topic-key" or "topic-value."
Key schemas are usually strings by default, but you can register key schemas explicitly if needed. Apache Kafka supports
alternative strategies, such as RecordNameStrategy and TopicRecordNameStrategy.
When you initially register a schema, the need for expansion and scalability arises as application requirements evolve.
To manage this growth effectively, Apache Kafka consumers must be able to process events using both existing and newly
registered schemas, thereby avoiding deserialization issues.
A key feature is accommodating multiple schema versions and allowing consumers to seamlessly deserialize Apache Kafka records
according to the registered schema and event structure. This dynamic feature enables producers and consumers to generate
and process events at scale while ensuring compatibility efficiently. It is important to note that each new schema
version is assigned a unique identifier.
Supported compatibility types include BACKWARD, BACKWARD_TRANSITIVE, FORWARD, FORWARD_TRANSITIVE, FULL, FULL_TRANSITIVE,
and NONE.
You can configure schema compatibility settings at both the subject and global levels. The system defaults to the global
setting if you don't specify subject-level compatibility.
To check the compatibility status, you can use the following APIs:
In Klaw, each Apache Kafka topic is associated with a specific owner, usually a designated team. The owner team is
automatically granted the role of schema owner, giving them the authority to create new schemas and oversee their
evolution.
Klaw ensures data consistency, reliability, and secure access, aligning with organizational policies. It also controls
schema registration, permitting only the designated owner to manage schemas and preventing unauthorized modifications
by other teams.
After creating a topic, the designated team that owns the topic gains the exclusive right to register a schema for it.
As the topic owner, you have the authority to approve, initiate, or reject any schema-related requests for that topic.
For more information on registering a schema see here
Watch the video below for a step-by-step demonstration of registering a schema in Klaw.
Backing up schemas from the Schema Registry is essential for ensuring recovery in the event of server failures or
unexpected disasters. While schemas are typically stored in a Apache Kafka topic with replication, there may be cases where
retrieving them is difficult or impossible.
Klaw simplifies this by connecting directly to the Schema Registry server, retrieving all available schemas associated
with topics, and integrating them into its metastore. This backup process is straightforward and takes only a few
clicks, regardless of the volume of schemas or topics.
For more information on synchronizing schemas from the Schema Registry to Klaw, refer to
sync-schemas-from-cluster
The following video demonstrates how schemas are synchronized to Klaw for a selection of topics already present in
Karapace.
After successfully backing up schemas in Klaw, you have the flexibility to register them either to a new Schema
Registry
cluster or integrate them into an existing one.
Select the schemas you want to sync with the cluster. Once you submit your choices, Klaw will register the selected
schemas directly into your designated Schema Registry environment.
Given the critical importance of data quality, protection, compliance, and management in every organization, Klaw
provides a robust foundation for building a resilient data governance framework. With its automated features, Klaw
empowers data teams to organize data, ensuring consistent accessibility, robust security, and unmatched reliability.
In today's dynamic and ever-changing digital landscape, maintaining the
uninterrupted operation of applications is of the highest importance.
This blog post explores the configuration of Klaw, a Java-based
application designed specifically for Apache Kafka® governance.
Our primary focus is on exploring the configuration process for
achieving High Availability (HA) in production environments. By
implementing these measures, we can ensure continuous operation, enhance
reliability, and deliver a seamless user experience, even during
unexpected failures.
High Availability (HA) is a design principle to ensure operational
continuity over a given period. For Klaw, being an essential tool in
managing and monitoring Apache Kafka clusters, the application must be
resilient to potential system failures. Achieving High Availability for
Klaw means eliminating single points of failure and ensuring minimal or
no downtime, thereby leading to a more reliable Apache Kafka governance.
Unforeseen events and emergencies can cause server failures, affecting
even the most robust systems. By supporting High Availability, Klaw is
equipped to automatically recover from component failures, thereby
reducing the impact of these events and providing users with a seamless
experience.
Apache Kafka clusters can be complex and substantial, making effective
management and monitoring crucial. A failure in these operations can
lead to significant issues. By configuring Klaw with High Availability,
it becomes a reliable Apache Kafka governance tool that ensures uninterrupted
operations, even in the face of underlying system failures. Deploying
Klaw with High Availability minimizes or eliminates downtime and
provides continuous support for Apache Kafka cluster management, enhancing
overall system reliability. With this understanding of High Availability
and its critical role in Klaw, let's explore the architectural design
that supports it, the internal components of Klaw, and how to configure
Klaw for High Availability.
What problem does High Availability for Klaw solve?
Before diving into what High Availability is, let's understand why
it's crucial for Klaw. As Klaw is essential in managing and monitoring
Apache Kafka clusters, ensuring its resilience against potential failures is
paramount. Downtime can have dire consequences ranging from slight
inconveniences to lost revenue and a damaged reputation. High
Availability for Klaw addresses these critical issues:
Minimizing downtime: By eliminating single points of failure and
ensuring redundancy in the system, HA for Klaw minimizes or
eliminates downtime.
Scalability: As the workload increases, Klaw can handle a higher
number of requests, catering to a growing user base, thanks to the
HA configuration.
Data availability: Ensuring that the data is always available, even
in the case of component failures, is crucial. HA ensures the data
is replicated across different servers, safeguarding against data
loss.
Service continuity: In the event of a disaster or system failure, HA
ensures that there is no interruption in service and the operations
continue without a hitch.
Enhanced user experience: Constant availability and reliability
improve user experience, which is vital for customer satisfaction
and retention.
High Availability (HA) is a design approach that guarantees a certain
degree of operational continuity during a given measurement period.
It's about ensuring that applications remain available even if a
critical component, such as a server, fails. Essentially, high
availability eliminates any single point of failure and ensures minimal
or no downtime. Why is High Availability important? Deploying
applications with High Availability in production environments is
essential for minimizing or eliminating downtime. Unforeseen events and
emergencies can cause server failures, affecting even the most robust
systems. HA systems are designed to automatically recover from component
failures, reducing the impact of these events.
Ensuring systems can handle higher workloads and substantial traffic is
undeniably vital. However, it is equally essential to identify potential
failure points and minimize downtime. A key component in achieving this
goal is a highly available load balancer, which plays a significant
role. It involves implementing a scalable infrastructure design that
adapts to increased traffic demands. This often consists of employing a
software architecture that surpasses hardware limitations.
Load balancing involves automatically distributing workloads across
system resources, such as assigning various data requests to different
servers.
In a highly available (HA) system, servers are organized in clusters and
arranged in a tiered architecture to handle requests from load balancers
efficiently. If a server within a cluster experiences a failure, a
replicated server in a separate cluster can seamlessly take over the
workload initially assigned to the failed server. This redundancy allows
for failover, where a secondary component assumes the responsibilities
of a primary component upon failure while minimizing any adverse effects
on performance.
This section provides an in-depth overview of Klaw's architecture, the
inner workings of its application, and the various perspectives it
offers to users.
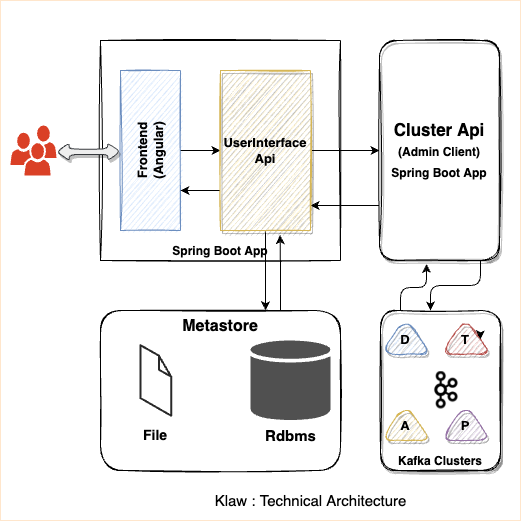
Klaw is a web application developed using Java, compatible with JDK
17/19. The application's front end is initially built using AngularJS,
but an upgrade to React JS is underway. The Backend development is
carried out using Spring Boot. Klaw relies on an RDBMS-based data store
for managing metadata. In its default configuration, Klaw employs a file
based H2 database for storing metadata.
Klaw is composed of two primary Java applications: the governance layer
and the cluster layer.
Governance layer
The governance layer is an integral part of Klaw, responsible for
handling user interfaces and APIs.
User interface components: Allows users to interact with Klaw's
features through a web interface. APIs and Authorization: The APIs in
the governance layer are responsible for authorizing requests and
interacting with the metastore (database). Upon approval, the
application communicates with the Klaw Cluster API application.
Security: The communication between APIs in the governance layer and
the cluster layer is highly secure. JWT token-based authentication is
used to ensure that no external user can interact directly with it.
User roles and permissions: Every user in Klaw is associated with a
role and a set of permissions. Additionally, users can be part of
multiple teams and have the flexibility to switch between them.
Cluster layer: The cluster layer is the second Java application within
Klaw.
Communication: This layer is a Java application that communicates with the governance layer and Apache Kafka
clusters (Kafka,
Schema Registry, Kafka Connect).
User interface switch: By default, users are logged into the
AngularJS-based interface. However, they can switch to
the React JS interface. Building React assets requires npm, pnpm, and
node.
Metastore Klaw organizes data in the database into three categories:
Administrator data: Comprises users, roles, permissions, teams, tenants,
clusters, environments, properties and other product related details.
Core data: Comprises topics, ACLs, schemas and connector
configurations.
Requests data: Comprises requests of topics, ACLs, schemas and
connectors.
Cache Klaw stores most frequently queried data in a local cache to
for improved performance and user experience. This effectively reduces
latency and gives users immediate response from the application.
However, this cache is reset whenever changes are requested. Deploying
Klaw in different environments like Development, Testing, Acceptance,
and Production is essential to streamline the developer experience.
For optimal performance of Klaw, we recommend the following system
requirements. These specifications assume a user base of approximately
100 or more, with around 50 or more Apache Kafka clusters and over 10,000
topics.
For the RDBMS, Klaw is compatible with various database management
systems such as PostgreSQL®, MySQL, and others.
Note: While the above configurations have been tested and proven to work
effectively, there are no guarantees that they will suit every use case.
The actual performance and suitability depend on various factors,
including the operating system, CPU utilization, and other processes
running on the virtual machines.
To further enhance the system's reliability, deploying the governance
application and the Klaw Cluster API application on separate machines is
recommended. This setup minimizes the risk of both applications being
affected by a single point of failure.
With the understanding of Klaw's working mechanism, let's explore how
to deploy Klaw in High Availability production-like environments using
the Nginx load balancer.
In this section, let's explore how to achieve High Availability for
Klaw using Nginx as the load balancer. Nginx serves as an efficient HTTP
load balancer, distributing traffic across multiple application servers,
thereby enhancing the performance, scalability, and reliability of web
applications.
In Klaw, you can configure database-level authentication by setting
klaw.login.authentication.type: db in the Klaw Core mode
application properties.
With database authentication, Klaw uses the Spring JSESSION ID. When
deploying Klaw in HA mode across more than one instance to ensure
uninterrupted user access, it's advisable to configure the IP-Hash load
balancing method.
Below is an example of Nginx configuration using the IP-Hash method:
Using IP-Hash method, sessions are maintained by tracking the client's
IP address. Single Sign-On (SSO) authentication in Klaw For SSO
authentication, configure Klaw by setting
klaw.login.authentication.type: ad in the Klaw Core mode
application properties. When SSO is enabled, either Round-Robin or
Least-Connected load balancing methods can be used.
Below is an example Nginx configuration using Round-Robin load
balancing:
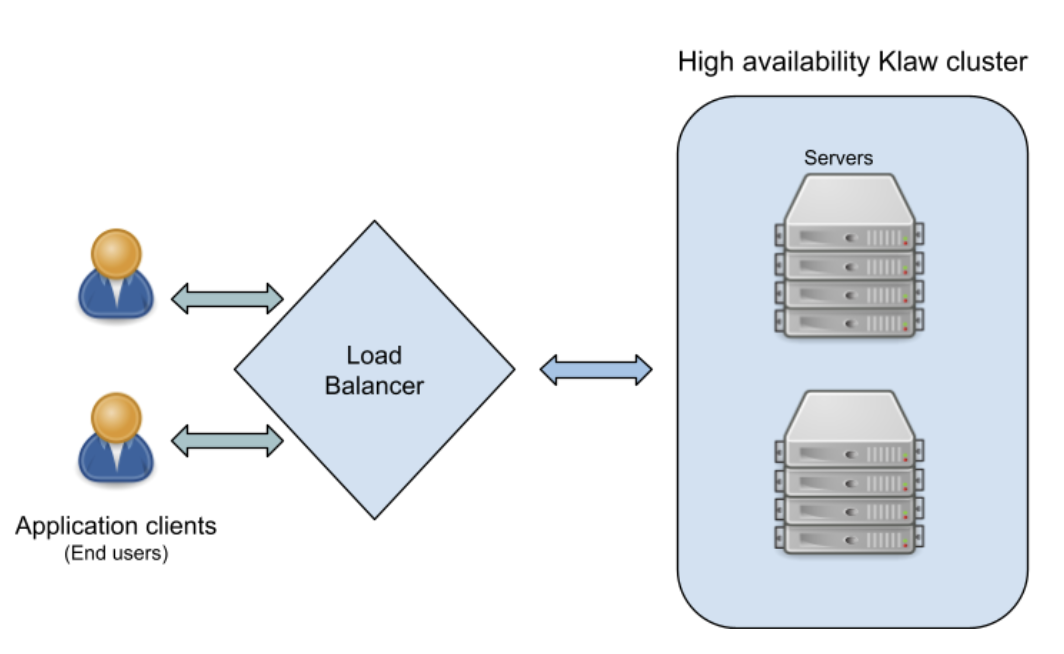
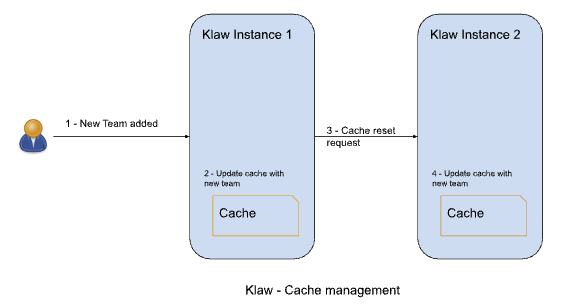
Klaw deployment model in High Availability (HA) mode
In the High Availability mode, Nginx routes the requests to Klaw
instances which are connected to a common data store such as Postgres.
Each Klaw instance comprises both the governance and Klaw Cluster API
applications. You may choose to deploy these applications on separate
machines for increased robustness. Below is the deployment model of Klaw
in HA mode.
While Klaw stores all metadata in a database, most of this data is
usually cached for quicker access. Therefore, it's important to reset
this cache whenever any changes are made to the configuration of topics,
ACLs, etc.
To ensure proper cache reset across Klaw instances, you must configure
the following property with the comma-separated list of instance hosts:
Spring Cloud Load Balancer: Allows client-side load balancing. For more
information, see the official guide.
Netflix Ribbon: Provides client-side load balancing for Spring Boot
applications. See the GitHub repository for more details.
AWS Load Balancer: AWS offers a variety of load balancers based on
network, containers, applications, and target groups. Choose the
appropriate one based on your requirements. Learn more on the official
AWS page.
In today's ever-evolving technological landscape, organizations
worldwide have adopted Apache Kafka® for its unparalleled scalability
and exceptional features, leading to a paradigm shift in how messaging
systems are handled. As more and more organizations adopt Apache Kafka as a
vital component of their technology stacks, the need for effective Apache Kafka
governance becomes paramount.
A common challenge companies face is the inability to effectively govern
and manage access permissions for the numerous topics created,
often numbering in the hundreds or even thousands.
Managing Apache Kafka topics poses significant challenges for companies, often
leading to struggles executing the task effectively. Several crucial
considerations arise when undertaking this endeavor:
Authorization and ownership: Determining who has the rights to
produce and consume messages on a specific topic and establishing
clear ownership are crucial aspects to address.
Configuration backup and restoration: Establishing robust
strategies for backing up and restoring Apache Kafka's configuration is
essential to ensure prompt recovery in the face of failures or
system disruptions.
Security measures: Ensuring the proper enforcement of security
measures through subscriptions and access controls is paramount to
safeguarding sensitive data and preventing unauthorized access.
Topic promotion: Navigating the process of smoothly promoting
topics with thoroughly tested configurations from lower environments
to production requires careful planning and coordination.
Enhancing visibility and awareness: Increasing the visibility
and awareness of topics within the organization facilitates better
collaboration and knowledge sharing among teams.
Managing a small number of Apache Kafka topics may seem straightforward at first.
However, as Apache Kafka usage grows and more applications and teams are added,
effective and efficient management can become increasingly challenging.
This includes the important task of isolating sensitive topics
containing GDPR, HIPAA, or other types of sensitive data. It is
essential to ensure that only authorized applications can access these
topics to maintain data security and regulatory compliance.
The current system faces several challenges that impede efficiency and
effectiveness, posing risks and hindering productivity. Identifying and
addressing these typical challenges can enhance operations and optimize
overall performance.
Let's explore the key challenges that need to be addressed:
Manual activities
Creating, accessing, and promoting a topic to a higher environment requires extensive email communication, involving
approximately 10 emails. This manual approach consumes valuable time and increases potential errors and
miscommunication.
Longer lead time
The end-to-end communication and execution of the manual activities take approximately 2.5 hours, excluding the time
spent waiting for human responses. This long lead time hampers efficiency and slows down the overall workflow.
Security
The system faces Role-Based Access Control (RBAC) and data security-related challenges. Ensuring proper access rights
and safeguarding sensitive information is crucial for maintaining the integrity and confidentiality of the system.
Lack of audit
No proper auditing mechanism is in place to track and monitor requests. This lack of audit trails creates an
accountability gap, making identifying and rectifying potential issues or discrepancies challenging.
Adhoc governance
The absence of a centralized governance setup adds complexity to the system. All actions are initiated through emails,
and the request approver list is maintained in spreadsheets or confluence.
Release management
The manual release processes, mainly promoting configurations from one environment to another, introduce a significant
risk of errors. These errors can cause system outages, leading to disruptions in service and impacting user
experience.
Failures are an inevitable part of any system, and Apache Kafka applications
are no different. These failures can occur at different levels,
including client-side issues where event deserialization creates
problems for consumers, as well as infrastructure-related issues that
result in the loss of ZooKeeper/Apache Kafka configurations.
In the context of infrastructure failures, let's consider a scenario
with 1000 topics, each possessing a unique configuration stored in a
ZooKeeper. Now, imagine a situation where a disaster strikes, causing
the ZooKeeper to crash and be unable to recover. This raises a critical
question: how swiftly can you retrieve the information and reboot your
server? It's not just about having methods to store information but
also about strategically implementing storage and retrieval processes
for efficient recovery.
To ensure a fail-safe Apache Kafka system, it is crucial to mitigate these
challenges by implementing a robust governance platform. This platform
should encompass the following essential capabilities:
Comprehensive visibility: Providing a holistic view of topics,
producers, consumers, schemas, and connectors.
Secure configuration management: Implementing a four-eye
principle-based system for reviews and approvals to maintain the
safety and consistency of configurations.
Notifications: Alerting users about changes to schemas and other
configurations.
Action tracking: Maintaining a detailed record of actions
performed by different users for transparent accountability.
Klaw is a comprehensive toolkit designed to address the challenges Apache Kafka
developers encounter. It provides solutions for compliance and audit
concerns, data security, and release management.
Developed as an open tool, Klaw is committed to contributing to the
streaming community by empowering developers to leverage modern
governance, control, and security practices while building Apache Kafka
applications.
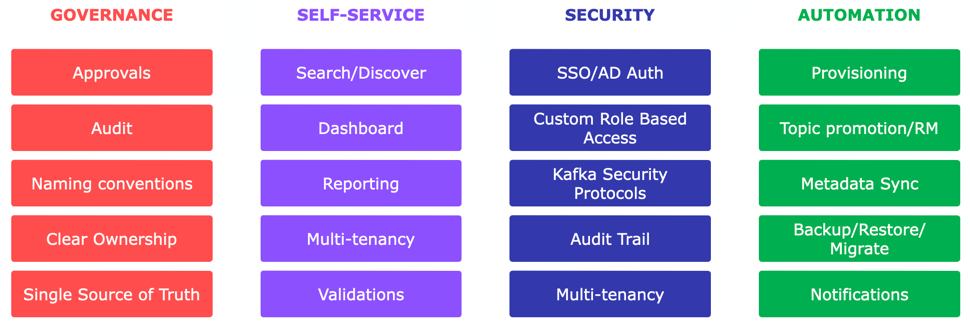
Klaw is built upon four essential pillars, which serve as the foundation
for its capabilities.
Governance - Self-service - Security - Automation
Governance: Ensures accountability and consistency with
approvals, audit trails, naming conventions, clear ownership, and a
single source of truth.
Self-service: Empowers developers with search, customizable
dashboard, reporting, and multi-tenancy for efficient resource
management and data integrity.
Security: Offers SSO/AD authentication, RBAC, Apache Kafka Security
protocols, audit trails, and multi-tenancy to address diverse
security needs.
Automation: Streamlines tasks like resource provisioning, topic
promotion, metadata sync, backup/restore, and notifications for time
and cost savings.
Reduced dependency: By reducing dependency on infrastructure
teams and empowering developer teams, Klaw enables faster execution
and decision-making, saving time, cost, and effort.
Zero risk of manual errors: With full self-service capabilities,
Klaw eliminates the risk of manual errors, ensuring data accuracy
and cost savings.
Continuous integration: Klaw enables continuous integration by
promoting topics and schemas to higher environments, ensuring
consistency throughout the development pipeline.
Secure authentication: Klaw authenticates users based on an
organization's single sign-on (SSO) or Active Directory (AD),
providing a secure access control mechanism.
Tailored security features: Klaw offers robust security features
that cater to the specific needs of different types of
organizations, ensuring data protection and compliance.
Organizations are devising unique strategies to tackle the growing
complexity of managing an increasing number of Apache Kafka topics, schemas,
and associated issues. These strategies involve using tools like Excel,
Confluence, and GitOps for partial data maintenance.
For a comprehensive and streamlined solution that simplifies the tasks
for both developers and administrators, Klaw stands as a highly effective
one-stop solution.